What is Research Data Management?
Research in science and technology fields today generates large quantities of data. This data not only needs to be processed and analyzed, it needs to be managed.
Funding agencies such as the NSF now require Data Management Plans to be submitted with grant proposals. These plans must explain how the researcher plans to manage the data generated by the research, addressing issues like security, version control, documentation, ownership and access, preservation, and sharing. If long term preservation and sharing is desired, the researcher must choose an appropriate repository to host it.
Why is it important?
- It helps you be organized about your research by documenting your processes for your
- External funding agencies may require you to share your data and publications
Why Libraries and Research Data?
Historically, libraries have served as institutions where information is collected, curated, preserved, described, discovered, and accessed. Putting these traditional library activities into data terms illustrates why academic libraries and librarians should be involved in the management of scholarly information and research data. As libraries we recognize research data as a scholarly asset that should be stored and made available for reuse, just as any publication is. This is particularly important as data has become more widely accessible in its digital form and its use for experimental validation and reuse in extending the boundaries of knowledge has become more practical.
As the majority of research data falls into the “long-tail” that encompasses the many disciplines that do not have dedicatedrepositories1, the role of academic libraries in making sure that these data are findable, accessible, interoperable & reusable becomes more prominent. There are a few reasons why this is a really excellent thing:
- Libraries & universities are long-lived institutions that do not traditionally rely on short term funding cycles, unlike many disciplinary repositories
- Libraries have demonstrated a sustainable model for collection of, preservation of, and access to information
- Libraries are filled with people who are trained in and participate in already developed and well-characterized practices and principles of information management, from description to organization to access to rights management, and on, and on
- Libraries are often already established partners in research, having provided guidance & resources at other stages of the research lifecycle
- Libraries provide instruction in and distribute information about other areas of information management. By adding data to this instructional portfolio, libraries can train the next generation of researchers in data standards & standard practices
These are just a few of the many reasons why academic libraries should be engaged in the challenges of research data stewardship, curation, and management.
Credit: ACRL Scholarly Communication Toolkit Accessed 2014-09-13
Research Data Lifecycle

Image credit: UC Irvine Library Digital Scholarship Services
https://www.lib.uci.edu/dss
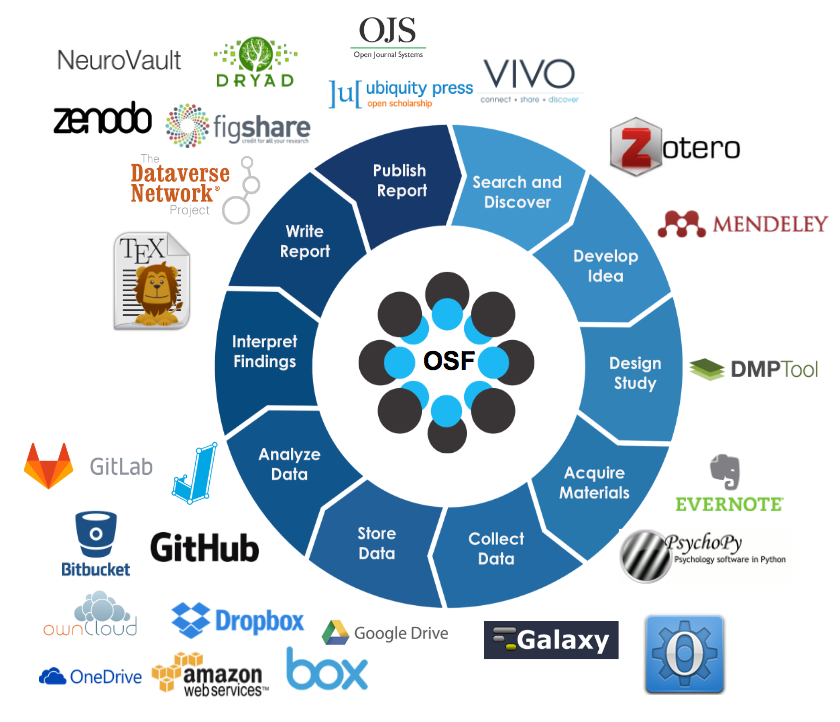
This image shows the variety of tools available for researchers to manage their research projects at every step in the research process.
Image credit: https://cos.io/our-products/open-science-framework/
Authorship credit:
Please note: this LibGuide was originally created by the former Scholarly Communications and Data Curation Librarian at Rowan University, Shilpa Rele, under a CC-By license and has since been remixed and updated also under a CC-BY license.